Piemēram, ja vēlaties regulāri saņemt iecienītāko produktu jaunumus par atlaižu piedāvājumiem vai vēlaties automatizēt iecienītās sezonas epizožu lejupielādes procesu pa vienam, un vietnei nav API, tad vienīgā izvēle jums paliek ar tīmekļa nokasīšanu.Tīmekļa nokasīšana dažās vietnēs var būt nelikumīga, atkarībā no tā, vai vietne to atļauj vai ne. Vietnēs tiek izmantoti “roboti.txt ”fails, lai skaidri noteiktu URL, kurus nav atļauts nodot metāllūžņos. Pievienojot “robotus, varat pārbaudīt, vai vietne to atļauj.txt ”ar vietnes domēna vārdu. Piemēram, https: // www.google.com / roboti.txt
Šajā rakstā mēs izmantosim Python, lai nokasītu, jo to ir ļoti viegli iestatīt un izmantot. Tajā ir daudz iebūvētu un trešo pušu bibliotēku, kuras var izmantot datu nokasīšanai un organizēšanai. Mēs izmantosim divas Python bibliotēkas “urllib”, lai ielādētu tīmekļa lapu, un “BeautifulSoup”, lai parsētu vietni, lai lietotu programmēšanas operācijas.
Kā darbojas tīmekļa nokasīšana?
Mēs nosūtām pieprasījumu uz vietni, no kuras vēlaties nokasīt datus. Vietne atbildēs uz pieprasījumu ar lapas HTML saturu. Tad mēs varam parsēt šo vietni BeautifulSoup tālākai apstrādei. Lai ielādētu vietni, mēs izmantosim Python bibliotēku “urllib”.
Urllib lejupielādēs tīmekļa lapas saturu HTML formātā. Šajā HTML tīmekļa lapā satura iegūšanai un tālākai apstrādei mēs nevaram piemērot virkņu darbības. Mēs izmantosim Python bibliotēku “BeautifulSoup”, kas parsēs saturu un iegūs interesantos datus.
Rakstu nokasīšana no Linuxhint.com
Tagad, kad mums ir ideja par to, kā darbojas tīmekļa nokasīšana, darīsim zināmu praksi. Mēs mēģināsim nokasīt rakstu nosaukumus un saites no Linuxhint.com. Tāpēc atveriet https: // linuxhint.com / jūsu pārlūkprogrammā.
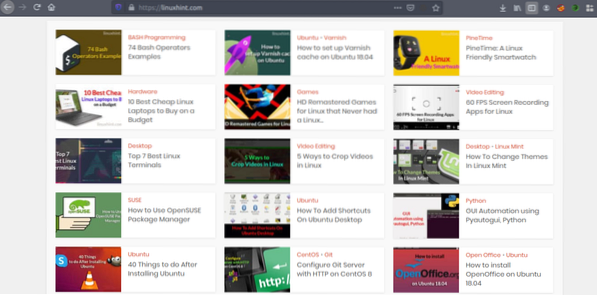
Tagad nospiediet CRTL + U, lai skatītu tīmekļa lapas HTML avota kodu.
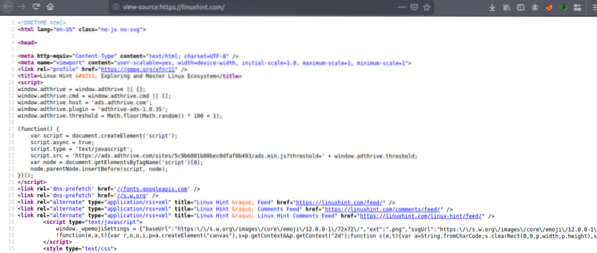
Nokopējiet avota kodu un dodieties uz vietni https: // htmlformatter.com / lai precizēt kodu. Pēc koda precizēšanas to ir viegli pārbaudīt un atrast interesantu informāciju.
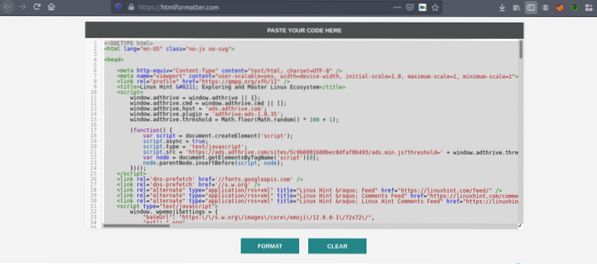
Tagad vēlreiz nokopējiet formatēto kodu un ielīmējiet to iecienītajā teksta redaktorā, piemēram, atom, cildens teksts utt. Tagad mēs nokasīsim interesanto informāciju, izmantojot Python. Ierakstiet šo
// Instalē skaistu zupas bibliotēku, nāk urllibiepriekš instalēta Python
ubuntu @ ubuntu: ~ $ sudo pip3 instalējiet bs4
ubuntu @ ubuntu: ~ $ python3
Python 3.7.3 (noklusējums, 2019. gada 7. oktobris, 12:56:13)
[GCC 8.3.0] uz Linux
Lai iegūtu papildinformāciju, ierakstiet “palīdzība”, “autortiesības”, “kredīti” vai “licence”.
// Importēt urllib>>> importēt urllib.pieprasījumu
// Importēt BeautifulSoup
>>> no bs4 importa BeautifulSoup
// Ievadiet URL, kuru vēlaties ielādēt
>>> my_url = 'https: // linuxhint.com / '
// Pieprasiet vietni URL, izmantojot komandu urlopen
>>> klients = urllib.pieprasījumu.urlopen (my_url)
// Saglabājiet HTML tīmekļa lapu mainīgajā “html_page”
>>> html_page = klients.lasīt ()
// Pēc tīmekļa lapas ielādes aizveriet URL savienojumu
>>> klients.aizvērt ()
// parsēt HTML vietni uz BeautifulSoup, lai to nokasītu
>>> page_soup = BeautifulSoup (html_page, "html.parsētājs ")
Tagad apskatīsim HTML avota kodu, kuru tikko nokopējām un ielīmējām, lai atrastu sev interesējošas lietas.
Jūs varat redzēt, ka pirmais raksts, kas norādīts Linuxhint.com nosaukums ir “74 Bash Operators piemēri”, atrodiet to avota kodā. Tas ir noslēgts starp galvenes tagiem, un tā kods ir
title = "74 Bash Operators piemēri"> 74 Bash Operators
Piemēri
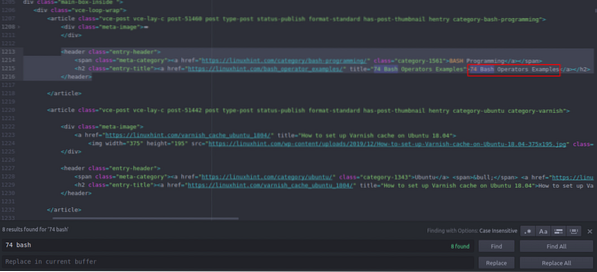
Tas pats kods atkārtojas atkārtoti, mainot tikai rakstu nosaukumus un saites. Nākamajā rakstā ir šāds HTML kods
title = "Kā iestatīt lakas kešatmiņu Ubuntu 18.04 ">
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
Var redzēt, ka visi raksti, ieskaitot šos divus, ir pievienoti vienā un tajā pašā
”Tagu un izmantojiet to pašu klasi“ entry-title ”. Mēs varam izmantot funkciju “findAll” skaistas zupas bibliotēkā, lai atrastu un sarakstītu visus “”Ar klases“ ieraksts-nosaukums ”. Python konsolē ierakstiet šo // Šī komanda atradīs visus “”Tagu elementi ar klases nosaukumu
“Entry-title”. Izeja tiks saglabāta masīvā.
>>> raksti = lapu_zupa.findAll ("h2" ,
"class": "entry-title")
// Linuxhint pirmajā lapā atrasto rakstu skaits.com
>>> len (raksti)
102
// Pirmais izvilkts “”Taga elements, kas satur raksta nosaukumu un saiti
>>> raksti [0]
title = "74 Bash Operators piemēri">
74 Bash operatoru piemēri
// Otrais iegūtais “”Taga elements, kas satur raksta nosaukumu un saiti
>>> raksti [1]
title = "Kā iestatīt lakas kešatmiņu Ubuntu 18.04 ">
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
// Tikai teksta parādīšana HTML tagos, izmantojot teksta funkciju
>>> raksti [1].tekstu
'Kā Ubuntu 18 iestatīt lakas kešatmiņu.04 '
”Tagu elementi ar klases nosaukumu
“Entry-title”. Izeja tiks saglabāta masīvā.
>>> raksti = lapu_zupa.findAll ("h2" ,
"class": "entry-title")
// Linuxhint pirmajā lapā atrasto rakstu skaits.com
>>> len (raksti)
102
// Pirmais izvilkts “”Taga elements, kas satur raksta nosaukumu un saiti
>>> raksti [0]
title = "74 Bash Operators piemēri">
74 Bash operatoru piemēri
// Otrais iegūtais “”Taga elements, kas satur raksta nosaukumu un saiti
>>> raksti [1]
title = "Kā iestatīt lakas kešatmiņu Ubuntu 18.04 ">
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
// Tikai teksta parādīšana HTML tagos, izmantojot teksta funkciju
>>> raksti [1].tekstu
'Kā Ubuntu 18 iestatīt lakas kešatmiņu.04 '
>>> raksti [0]
title = "74 Bash Operators piemēri">
74 Bash operatoru piemēri
// Otrais iegūtais “
”Taga elements, kas satur raksta nosaukumu un saiti
>>> raksti [1]
title = "Kā iestatīt lakas kešatmiņu Ubuntu 18.04 ">
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
// Tikai teksta parādīšana HTML tagos, izmantojot teksta funkciju
>>> raksti [1].tekstu
'Kā Ubuntu 18 iestatīt lakas kešatmiņu.04 '
title = "Kā iestatīt lakas kešatmiņu Ubuntu 18.04 ">
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
Tagad, kad mums ir saraksts ar visiem 102 HTML “
”Tagu elementus, kas satur raksta saiti un raksta nosaukumu. Mēs varam iegūt gan rakstu saites, gan nosaukumus. Lai izgūtu saites no “”Tagus, mēs varam izmantot šādu kodu // Šis kods saiti izraksta no pirmās taga elements
>>> saitei rakstos [0].find_all ('a', href = True):
... izdrukāt (saite ['href'])
…
https: // linuxhint.com / bash_operator_examples /
Tagad mēs varam uzrakstīt ciklu for iterāciju caur katru “
”Tagu elementu sarakstā“ Raksti ”un izvelciet raksta saiti un virsrakstu. >>> i diapazonā (0,10):
... izdrukāt (raksti [i].teksts)
... saite rakstos [i].find_all ('a', href = True):
... izdrukāt (saite ['href'] + "\ n")
…
74 Bash operatoru piemēri
https: // linuxhint.com / bash_operator_examples /
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: Linux draudzīgs viedpulkstenis
https: // linuxhint.com / pinetime_linux_smartwatch /
10 labākie lēti Linux klēpjdatori, ko iegādāties par budžetu
https: // linuxhint.com / best_cheap_linux_laptops /
HD Remastered spēles Linux, kurām nekad nav bijis Linux laidiena ..
https: // linuxhint.com / hd_remastered_games_linux /
60 FPS ekrāna ierakstīšanas lietotnes Linux
https: // linuxhint.lv / 60_fps_screen_recording_apps_linux /
74 Bash operatoru piemēri
https: // linuxhint.com / bash_operator_examples /
... izgriezums ..
Tāpat šos rezultātus jūs saglabājat JSON vai CSV failā.
Secinājums
Jūsu ikdienas uzdevumi ir ne tikai failu pārvaldība vai sistēmas komandu izpilde. Varat arī automatizēt ar tīmekli saistītus uzdevumus, piemēram, failu lejupielādes automatizāciju vai datu ieguvi, nokasot Web Python. Šis raksts aprobežojās ar vienkāršu datu iegūšanu, taču jūs varat veikt milzīgu uzdevumu automatizāciju, izmantojot “urllib” un “BeautifulSoup”.
>>> saitei rakstos [0].find_all ('a', href = True):
... izdrukāt (saite ['href'])
…
https: // linuxhint.com / bash_operator_examples /
... izdrukāt (raksti [i].teksts)
... saite rakstos [i].find_all ('a', href = True):
... izdrukāt (saite ['href'] + "\ n")
…
74 Bash operatoru piemēri
https: // linuxhint.com / bash_operator_examples /
Kā Ubuntu 18 iestatīt lakas kešatmiņu.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: Linux draudzīgs viedpulkstenis
https: // linuxhint.com / pinetime_linux_smartwatch /
10 labākie lēti Linux klēpjdatori, ko iegādāties par budžetu
https: // linuxhint.com / best_cheap_linux_laptops /
HD Remastered spēles Linux, kurām nekad nav bijis Linux laidiena ..
https: // linuxhint.com / hd_remastered_games_linux /
60 FPS ekrāna ierakstīšanas lietotnes Linux
https: // linuxhint.lv / 60_fps_screen_recording_apps_linux /
74 Bash operatoru piemēri
https: // linuxhint.com / bash_operator_examples /
... izgriezums ..


