Pandas .lasīt_csv
Esmu jau apspriedis daļu Python bibliotēkas pandu vēstures un izmantošanas veidu. pandas tika izstrādātas, ņemot vērā nepieciešamību pēc efektīvas Python finanšu datu analīzes un manipulāciju bibliotēkas. Lai ielādētu datus analīzei un manipulācijām, pandas nodrošina divas metodes, DataReader un lasīt_csv. Es šeit aplūkoju pirmo. Pēdējais ir šīs apmācības priekšmets.
.lasīt_csv
Tiešsaistē ir liels skaits bezmaksas datu krātuvju, kurās ir informācija par dažādiem laukiem. Dažus no šiem resursiem esmu iekļāvis zemāk esošajā atsauču sadaļā. Tā kā esmu parādījis iebūvētās API efektīvai finanšu datu iegūšanai šeit, šajā apmācībā es izmantošu citu datu avotu.
Dati.gov piedāvā milzīgu bezmaksas datu izvēli par visu, sākot no klimata pārmaiņām līdz pat U.S. ražošanas statistika. Esmu lejupielādējis divas datu kopas lietošanai šajā apmācībā. Pirmais ir vidējā dienas maksimālā temperatūra Bay County, Florida. Šie dati tika lejupielādēti no U.S. Klimata noturības rīku komplekts laika posmam no 1950. gada līdz pašreizējam.
Otrais ir preču plūsmas apsekojums, kas nosaka importa veidu un apjomu valstī 5 gadu laikā.

Abas šo datu kopu saites ir norādītas atsauču sadaļā. The .lasīt_csv metode, kā tas ir skaidrs no nosaukuma, ielādēs šo informāciju no CSV faila un veiks a DataFrame no šīs datu kopas.
Lietošana
Jebkurā laikā, kad izmantojat ārēju bibliotēku, jums jāpasaka Python, ka tā ir jāimportē. Zemāk ir koda rindiņa, kas importē pandu bibliotēku.
importa pandas kā pdPamata lietojums .lasīt_csv metode ir zemāk. Tas momentāno un apdzīvo a DataFrame df ar informāciju CSV failā.
df = pd.read_csv ('12005-gada-hist-obs-tasmax.csv ')Pievienojot vēl pāris rindiņas, mēs varam pārbaudīt pirmās un pēdējās 5 rindas no jaunizveidotā DataFrame.
df = pd.read_csv ('12005-gada-hist-obs-tasmax.csv ')izdruka (df.galva (5))
izdruka (df.aste (5))

Kods ir ielādējis kolonnu par gadu, vidējo dienas temperatūru pēc Celsija (tasmax), un izveidojis indeksēšanas shēmu, kuras pamatā ir 1, kas palielinās katrai datu rindai. Ir arī svarīgi atzīmēt, ka galvenes tiek aizpildītas no faila. Izmantojot iepriekš aprakstītās metodes pamata izmantošanu, tiek secināts, ka galvenes atrodas CSV faila pirmajā rindā. To var mainīt, nododot metodei citu parametru kopu.
Parametri
Esmu norādījis saiti uz pandām .lasīt_csv dokumentāciju zemāk esošajās atsaucēs. Ir vairāki parametri, kurus var izmantot, lai mainītu datu lasīšanas un formatēšanas veidu DataFrame.

Ir diezgan daudz parametru .lasīt_csv metodi. Lielākā daļa nav nepieciešami, jo lielākajai daļai lejupielādēto datu kopu būs standarta formāts. Tas ir kolonnas pirmajā rindā un komatu atdalītājs.
Ir daži parametri, kurus es izcelšu apmācībā, jo tie var būt noderīgi. Plašāku aptauju var veikt no dokumentācijas lapas.
indekss_kol
indekss_kol ir parametrs, ko var izmantot, lai norādītu kolonnu, kurā atrodas indekss. Dažos failos var būt indekss, bet dažos - ne. Mūsu pirmajā datu kopā es ļāvu pitonam izveidot indeksu. Tas ir standarts .lasīt_csv uzvedība.
Mūsu otrajā datu kopā ir iekļauts indekss. Zemāk esošais kods ielādē DataFrame ar CSV failā esošajiem datiem, bet tā vietā, lai izveidotu pieaugoša skaitļa indeksu, tā izmanto datu kopā iekļauto kolonnu SHPMT_ID.
df = pd.lasīt_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ')izdruka (df.galva (5))
izdruka (df.aste (5))
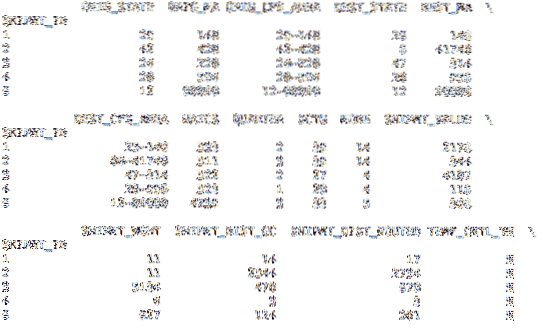
Lai gan šajā datu kopā indeksam tiek izmantota viena un tā pati shēma, citām datu kopām var būt noderīgāks indekss.
nrows, skiprows, usecols
Izmantojot lielas datu kopas, iespējams, vēlēsities ielādēt tikai datu sadaļas. The nrows, skiprows, un usecols parametri ļaus sagriezt failā iekļautos datus.
df = pd.lasīt_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ', nrows = 50)izdruka (df.galva (5))
izdruka (df.aste (5))
Pievienojot nrows parametrs ar veselu skaitli 50, .astes zvans tagad atgriež rindas līdz 50. Pārējie failā esošie dati netiek importēti.
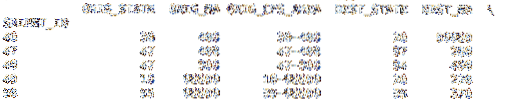
izdruka (df.galva (5))
izdruka (df.aste (5))
Pievienojot skiprows parametrs, mūsu .galva col datos neuzrāda sākuma indeksu 1001. Tā kā mēs izlaidām galvenes rindu, jaunie dati ir zaudējuši savu galveni un indeksu, pamatojoties uz faila datiem. Dažos gadījumos var būt labāk sagriezt datus a DataFrame nevis pirms datu ielādes.

The usecols ir noderīgs parametrs, kas ļauj importēt tikai datu apakškopu pa kolonnām. Tam var nodot nulles indeksu vai virkņu sarakstu ar kolonnu nosaukumiem. Es izmantoju zemāk esošo kodu, lai pirmās četras kolonnas importētu mūsu jaunajā DataFrame.
df = pd.lasīt_csv ('cfs_2012_pumf_csv.txt ',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3])
izdruka (df.galva (5))
izdruka (df.aste (5))
No mūsu jaunā .galva zvaniet, mūsu DataFrame tagad satur tikai pirmās četras datu kopas kolonnas.
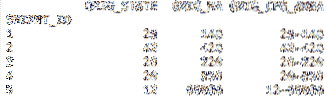
dzinējs
Pēdējais parametrs, kas, manuprāt, noderēs dažās datu kopās, ir dzinējs parametrs. Varat izmantot vai nu C dzinēju, vai Python kodu. C motors, protams, būs ātrāks. Tas ir svarīgi, ja importējat lielas datu kopas. Python parsēšanas priekšrocības ir vairāk funkcijām bagāts komplekts. Šis ieguvums var nozīmēt mazāk, ja atmiņā ielādējat lielus datus.
df = pd.lasīt_csv ('cfs_2012_pumf_csv.txt ',index_col = 'SHIPMT_ID', dzinējs = 'c')
izdruka (df.galva (5))
izdruka (df.aste (5))
Sekojiet līdzi
Ir vairāki citi parametri, kas var paplašināt .lasīt_csv metodi. Tos var atrast dokumentu lapā, uz kuru es atsaucos tālāk. .lasīt_csv ir noderīga metode datu kopu ielādēšanai pandās datu analīzei. Tā kā daudzām bezmaksas datu kopām internetā nav API, tas visnoderīgāk izrādīsies lietojumprogrammām ārpus finanšu datiem, kur ir izveidotas stabilas API datu importēšanai pandās.
Atsauces
https: // pandas.pydata.org / pandas-docs / stabils / ģenerēts / pandas.lasīt_csv.html
https: // www.dati.gov /
https: // rīkkopa.klimats.gov / # klimata pētnieks
https: // www.tautas skaitīšana.gov / econ / cfs / pums.html


