dd funkcijas
“Dd” var izmantot dažādiem mērķiem:
- Izmantojot “dd”, ir iespējams tieši lasīt un / vai rakstīt no / uz dažādiem failiem, ja vien funkcija jau ir ieviesta respektējamos draiveros.
- Tas ir ļoti noderīgs tādiem mērķiem kā sāknēšanas sektora dublēšana, nejaušu datu iegūšana utt.
- Datu konvertēšana, piemēram, ASCII konvertēšana uz EBCDIC kodējumu.
dd izmantošana
Šeit ir daži no visizplatītākajiem un interesantākajiem “dd” lietojumiem. Protams, “dd” ir daudz spējīgāks par šīm lietām. Ja jūs interesē, es vienmēr iesaku pārbaudīt citus padziļinātus resursus vietnē “dd”.
Atrašanās vieta
kas dd
Kā norāda izeja, ikreiz, kad darbojas “dd”, tā tiek palaista no “/ usr / bin / dd”.
Pamata lietošana
Lūk, struktūra, kurai seko “dd”.
dd ja =Piemēram, izveidosim failu ar nejaušiem datiem. Linux ir daži iebūvēti īpaši faili, kas parādās kā parasti faili, piemēram, “/ dev / zero”, kas rada nepārtrauktu NULL plūsmu, “/ dev / random”, kas rada nepārtrauktus nejaušus datus.
dd, ja = / dev / urandom no = ~ / Desktop / random.txt bs = 1M skaits = 5
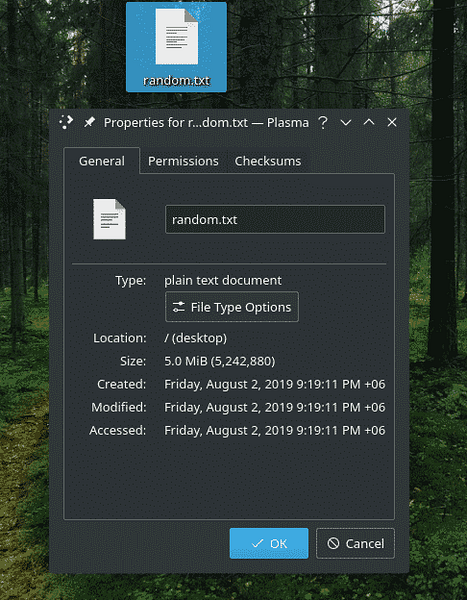
Pirmās iespējas ir pašsaprotamas. Tas nozīmē izmantot “/ dev / urandom” kā datu avotu un “~ / Desktop / random.txt ”kā galamērķi. Kādas ir citas iespējas?
Šeit “bs” nozīmē “bloka lielums”. Kad dd raksta datus, tas raksta blokos. Izmantojot šo opciju, var noteikt bloka lielumu. Šajā gadījumā vērtība “1M” norāda, ka bloka lielums ir 1 megabaits.
“Skaits” izlemj ierakstāmo bloku skaitu. Ja tas nav izlabots, “dd” turpinās rakstīšanas procesu, ja vien ievades straume nebeigsies. Šajā gadījumā “/ dev / urandom” turpinās bezgalīgi ģenerēt datus, tāpēc šajā piemērā šī opcija bija vissvarīgākā.
Datu dublēšana
Izmantojot šo metodi, “dd” var izmantot visa diska datu izgāšanai! Viss, kas jums nepieciešams, ir pateikt diskam kā avotu.
dd ja =
Ja jūs gatavojaties veikt šādas darbības, pārliecinieties, ka jūsu avots nav katalogs. “Dd” nav ne jausmas, kā apstrādāt direktoriju, tāpēc viss nedarbosies.

“Dd” zina, kā strādāt tikai ar failiem. Tātad, ja jums ir nepieciešams dublēt direktoriju, vispirms izmantojiet darvu, lai to arhivētu, pēc tam izmantojiet “dd”, lai to pārsūtītu uz failu.
darva cvJf demonstrācija.darva.xz DemoDir /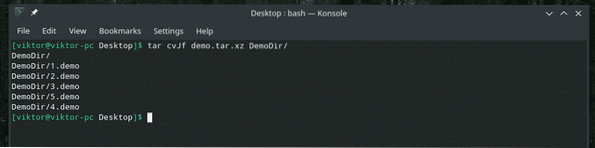

Nākamajā piemērā mēs veiksim ļoti jutīgu darbību: MBR dublēšanu! Tagad, ja jūsu sistēma izmanto MBR (Master Boot Record), tā atrodas sistēmas diska pirmajos 512 baitos: 466 baiti sāknēšanas ielādētājam, citi nodalījuma tabulai.
Palaidiet šo komandu, lai dublētu MBR ierakstu.
dd, ja = / dev / sda no = ~ / Desktop / mbr.img bs = 512 skaits = 1
Datu atjaunošana
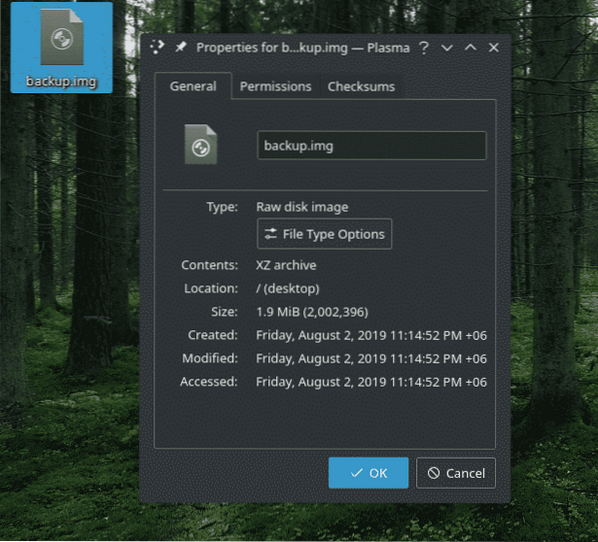
Jebkurai dublējumkopijai ir nepieciešams datu atjaunošanas veids. “Dd” gadījumā atjaunošanas process ir nedaudz atšķirīgs no citiem rīkiem. Jums ir jāpārraksta dublējuma fails līdzīgā mapē / nodalījumā / ierīcē.
Piemēram, man ir šī “rezerves kopija.img ”fails ar“ demo.darva.xz ”fails. Lai to izvilktu, es izmantoju šādu komandu.
dd if = dublējums.img no = demonstrācijas.darva.xz
Atkal pārliecinieties, vai izrakstu rakstāt failā. Atcerieties, ka “dd” nav labs katalogos?
Līdzīgi, ja “dd” tika izmantots nodalījuma dublējuma izveidošanai, tā atjaunošanai būs nepieciešama šāda komanda.
dd ja =
Piemēram, kā par MBR atjaunošanu, kuru mēs dublējām agrāk?
dd ja = mbr.img no = / dev / sda
“Dd” opcijas
Kādā brīdī šajā ceļvedī jūs saskārāties ar dažām “dd” opcijām, piemēram, “bs” un “skaits”? Nu, tādu ir vairāk. Šeit ir saraksts ar to, kas viņi ir un kā tos izmantot.
- obs: nosaka vienlaikus rakstāmo datu lielumu. Noklusējuma vērtība ir 512 baiti.

- cbs: nosaka vienlaicīgi konvertējamo datu lielumu.

- ibs: nosaka vienlaikus nolasāmo datu lielumu.
- skaits: kopēt tikai N blokus

- meklēt: izlaides sākumā izlaist N blokus

- izlaist: izlaist N blokus ievades sākumā







Papildu iespējas:
- nocreat: Neveidojiet izvades failu
- notruc: Negrieziet izejas failu
- noerror: turpiniet darbību pat pēc kļūdas
- fdatasync: pirms procesa beigām ierakstiet datus fiziskajā atmiņā
- fsync: Līdzīgs fdatasync, bet arī raksta metadatus
- iflag: pielāgojiet darbību, pamatojoties uz dažādiem karodziņiem. Pieejamie karodziņi ietver: pievienot izveidei Pievienot datus

Papildu iespējas:
- direktorijs: Saskaroties ar direktoriju, darbība neizdosies
- dsync: sinhronizēts I / O datiem
- sinhronizēt: Līdzīgi kā dsync, bet ietver metadatus
- nocache: pieprasījumi atmest kešatmiņu.
- nofollow: Nesekojiet nevienai saitei

Papildu iespējas:
- count_bytes: Līdzīgi kā “count = N”
- seek_bytes: Līdzīgi kā “seek = N”
- skip_bytes: Līdzīgs “skip = N”
Kā redzējāt, vienā komandā “dd” ir iespējams sakraut vairākus karodziņus un opcijas, lai pielāgotu darbības uzvedību.
dd ja = demonstrācija.txt no = demo1.txt bs = 10 skaits = 100 konv = ebcdiciflag = pievienot, nocache, nofollow, sinhronizēt

Pēdējās domas
“Dd” darbplūsma ir diezgan vienkārša. Tomēr, lai “dd” patiesi spīdētu, tas ir atkarīgs no jums. Ir daudz veidu, kā radošus veidus “dd” var izmantot gudras mijiedarbības veikšanai.
Lai iegūtu detalizētu informāciju par “dd” un visām tā iespējām, skatiet vīrieti un informācijas lapu.
cilvēks dd

