Šis ir turpinājuma raksts iepriekšējam. Mēs aplūkosim, kā precizēt vaicājumu, noformulēt sarežģītākus meklēšanas kritērijus ar dažādiem parametriem un izprast Apache Solr vaicājuma lapas dažādās tīmekļa veidlapas. Mēs arī apspriedīsim, kā pēcapstrādāt meklēšanas rezultātu, izmantojot dažādus izvades formātus, piemēram, XML, CSV un JSON.
Vaicājot Apache Solr
Apache Solr ir veidots kā tīmekļa lietojumprogramma un pakalpojums, kas darbojas fonā. Rezultāts ir tāds, ka jebkura klienta lietojumprogramma var sazināties ar Solr, nosūtot tai vaicājumus (šī raksta uzmanības centrā), manipulējot ar dokumenta kodolu, pievienojot, atjauninot un dzēšot indeksētos datus un optimizējot pamatdatus. Ir divas iespējas - izmantojot informācijas paneli / tīmekļa saskarni vai izmantojot API, nosūtot atbilstošu pieprasījumu.
Parasti tiek izmantots pirmais variants testēšanas nolūkiem, nevis regulārai piekļuvei. Zemāk redzamajā attēlā redzams Apache Solr administrēšanas lietotāja interfeisa informācijas panelis ar dažādām vaicājuma veidlapām tīmekļa pārlūkprogrammā Firefox.
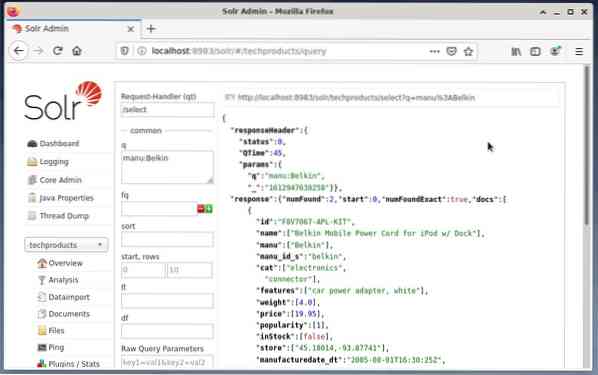
Vispirms izvēlnē zem galvenā izvēles lauka izvēlieties izvēlnes ierakstu “Vaicājums”. Pēc tam informācijas panelī tiks parādīti vairāki ievades lauki šādi:
- Pieprasījumu apstrādātājs (qt):
Definējiet, kāda veida pieprasījumu vēlaties nosūtīt Solr. Varat izvēlēties starp noklusējuma pieprasījumu apstrādātājiem “/ select” (vaicājuma indeksētie dati), “/ update” (atjaunināt indeksētos datus) un “/ delete” (noņemt norādītos indeksētos datus) vai pašnoteiktu. - Vaicājuma notikums (q):
Definējiet lauku nosaukumus un vērtības, kas jāizvēlas. - Filtrēt vaicājumus (fq):
Ierobežojiet to dokumentu kopu, kurus var atgriezt, neietekmējot dokumentu rādītājus. - Kārtot secību (kārtot):
Definējiet vaicājuma rezultātu kārtošanas secību augošā vai dilstošā secībā - Izejas logs (sākums un rindas):
Ierobežojiet izvadi līdz norādītajiem elementiem - Lauku saraksts (fl):
Ierobežo vaicājuma atbildē iekļauto informāciju līdz norādītajam lauku sarakstam. - Izejas formāts (wt):
Definējiet vēlamo izvades formātu. Noklusējuma vērtība ir JSON.
Noklikšķinot uz pogas Izpildīt vaicājumu, tiek izpildīts vēlamais pieprasījums. Praktiskus piemērus skatiet zemāk.
Kā otrais variants, jūs varat nosūtīt pieprasījumu, izmantojot API. Tas ir HTTP pieprasījums, kuru Apache Solr var nosūtīt jebkura lietojumprogramma. Solr apstrādā pieprasījumu un atgriež atbildi. Īpašs gadījums ir savienojums ar Apache Solr, izmantojot Java API. Tas ir ticis nodots atsevišķam projektam ar nosaukumu SolrJ [7] - Java API, neprasot HTTP savienojumu.
Vaicājuma sintakse
Vaicājuma sintakse vislabāk aprakstīta [3] un [5]. Dažādie parametru nosaukumi tieši atbilst iepriekš paskaidroto veidlapu ierakstu lauku nosaukumiem. Zemāk esošajā tabulā tie ir uzskaitīti, kā arī praktiski piemēri.
Vaicājumu parametru indekss
| Parametrs | Apraksts | Piemērs |
|---|---|---|
| q | Apache Solr galvenais vaicājuma parametrs - lauku nosaukumi un vērtības. Viņu līdzības rādītāji dokumentē šī parametra terminus. | Id: 5 automašīnas: * adilla * *: X5 |
| fq | Ierobežojiet rezultātu kopu tikai tiem superseteta dokumentiem, kas atbilst filtram, piemēram, kas definēts, izmantojot funkciju diapazona vaicājumu parsētāju | modeli id, modelis |
| sākt | Lapu rezultātu kompensācijas (sākums). Šī parametra noklusējuma vērtība ir 0. | 5 |
| rindas | Lapas rezultātu nobīdes (beigas). Pēc noklusējuma šī parametra vērtība ir 10 | 15 |
| kārtot | Tas norāda to lauku sarakstu, kas atdalīti ar komatiem, pamatojoties uz kuriem jāšķiro vaicājuma rezultāti | modelis asc |
| fl | Tas norāda lauku sarakstu, kas jāatgriež par visiem rezultātu kopas dokumentiem | modeli id, modelis |
| wt | Šis parametrs norāda atbildes rakstītāja veidu, kuru mēs vēlējāmies apskatīt. Pēc noklusējuma tā vērtība ir JSON. | json xml |
Meklējumi tiek veikti, izmantojot HTTP GET pieprasījumu ar vaicājuma virkni q parametrā. Tālāk sniegtie piemēri paskaidros, kā tas darbojas. Tiek izmantots čokurošanās, lai nosūtītu vaicājumu vietējai instalētai Solr.
- Iegūstiet visas datu kopas no galveno automašīnu čokurošanās http: // localhost: 8983 / solr / cars / query?q = *: *
- Iegūstiet visas datu kopas no galvenajiem automobiļiem, kuru ID ir 5 čokurošanās http: // localhost: 8983 / solr / cars / query?q = id: 5
- Iegūstiet lauka modeli no visām galveno automašīnu datu kopām
1. variants (ar izbēgtu un): čokurošanās http: // localhost: 8983 / solr / cars / query?q = id: * \ & fl = modelis2. iespēja (vaicājums vienā ērcē):
čokurošanās 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = modelis ' - Iegūstiet visas galveno automobiļu datu kopas, kas sakārtotas pēc cenas dilstošā secībā, un izvadiet tikai marķējuma, modeļa un cenas laukus (versija vienā ērcē): čokurošanās http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
kārtot = cena desc &
fl = marka, modelis, cena ' - Iegūstiet pirmās piecas galveno automašīnu datu kopas, kas sakārtotas pēc cenas dilstošā secībā, un izvadiet tikai marķējuma, modeļa un cenas laukus (versija atsevišķās ērcēs): čokurošanās http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
rindas = 5 &
kārtot = cena desc &
fl = marka, modelis, cena ' - Iegūstiet pirmās piecas galveno automobiļu datu kopas, kas sakārtotas pēc cenas dilstošā secībā, un izvadiet tikai marķējuma laukus, modeli un cenu, kā arī tā atbilstības rādītāju (versija vienā ērcē): čokurošanās http: // localhost: 8983 / solr / automašīnas / vaicājums -d '
q = *: * &
rindas = 5 &
kārtot = cena desc &
fl = marka, modelis, cena, rezultāts ' - Atgrieziet visus saglabātos laukus, kā arī atbilstības rādītāju: čokurošanās http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, rezultāts '
Turklāt varat definēt savu pieprasījumu apstrādātāju, lai vaicājuma parsētājam nosūtītu izvēles pieprasījuma parametrus, lai kontrolētu, kāda informācija tiek atgriezta.
Vaicājumu parsētāji
Apache Solr izmanto tā saukto vaicājumu parsētāju - komponentu, kas jūsu meklēšanas virkni pārveido īpašās meklētājprogrammas instrukcijās. Vaicājuma parsētājs atrodas starp jums un dokumentu, kuru meklējat.
Pakalpojumā Solr ir iekļauti dažādi parsēšanas veidi, kas atšķiras no iesniegtā vaicājuma apstrādes veida. Standarta vaicājumu parsētājs darbojas labi strukturētiem vaicājumiem, taču mazāk tolerē sintakses kļūdas. Tajā pašā laikā gan DisMax, gan paplašinātais DisMax vaicājumu parsētājs ir optimizēts dabiskām valodām līdzīgiem vaicājumiem. Tie ir paredzēti, lai apstrādātu vienkāršas lietotāju ievadītas frāzes un meklētu atsevišķus vārdus vairākos laukos, izmantojot atšķirīgu svērumu.
Turklāt Solr piedāvā arī tā sauktos funkciju vaicājumus, kas ļauj apvienot funkciju ar vaicājumu, lai izveidotu noteiktu atbilstības rādītāju. Šie parsētāji tiek nosaukti par Function Query Parser un Function Range Query Parser. Tālāk sniegtajā piemērā parādīts, ka pēdējais izvēlas visas “bmw” datu kopas (kas saglabātas datu laukā make) ar modeļiem no 318 līdz 323:
čokurošanās http: // localhost: 8983 / solr / cars / query -d 'q = izgatavot: bmw &
fq = modelis: [318 līdz 323] "
Rezultātu pēcapstrāde
Vaicājumu nosūtīšana Apache Solr ir viena daļa, bet meklēšanas rezultātu pēcapstrāde no otras. Pirmkārt, jūs varat izvēlēties starp dažādiem atbildes formātiem - no JSON līdz XML, CSV un vienkāršotu Ruby formātu. Vaicājumā vienkārši norādiet atbilstošo parametru wt. Tālāk redzamais kodu piemērs to parāda, lai visiem vienumiem izgūtu datu kopu CSV formātā, izmantojot čokurošanos ar izbēgtu &:
čokurošanās http: // localhost: 8983 / solr / cars / query?q = id: 5 \ & wt = csvIzeja ir komatu atdalīts saraksts šādi:

Lai saņemtu rezultātu kā XML datus, bet tikai divi izejas lauki veido un modelē, izpildiet šādu vaicājumu:
čokurošanās http: // localhost: 8983 / solr / cars / query?q = *: * \ & fl = make, modelis \ & wt = xmlIzeja ir atšķirīga, un tajā ir gan atbildes galvene, gan faktiskā atbilde:
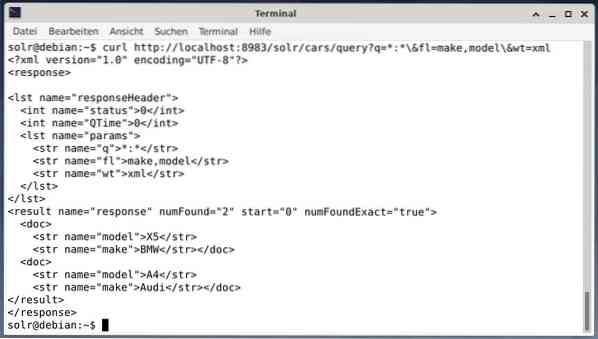
Wget saņemtos datus vienkārši izdrukā stdout. Tas ļauj pēcapstrādāt atbildi, izmantojot standarta komandrindas rīkus. Lai uzskaitītu dažus, šeit ir jq [9] JSON, xsltproc, xidel, xmlstarlet [10] XML, kā arī csvkit [11] CSV formātam.
Secinājums
Šajā rakstā ir parādīti dažādi veidi, kā nosūtīt vaicājumus Apache Solr, un paskaidrots, kā apstrādāt meklēšanas rezultātu. Nākamajā daļā jūs uzzināsiet, kā izmantot Apache Solr, meklējot relāciju datu bāzes pārvaldības sistēmā PostgreSQL.
Par autoriem
Žakijs Kabeta ir vides aizstāvis, dedzīgs pētnieks, treneris un padomdevējs. Vairākās Āfrikas valstīs viņa ir strādājusi IT nozarē un NVO vidē.
Frenks Hofmans ir IT izstrādātājs, treneris un autors un dod priekšroku strādāt no Berlīnes, Ženēvas un Keiptaunas. Debian Package Management Book līdzautors, kas pieejams vietnē dpmb.org
Saites un atsauces
- [1] Apache Solr, https: // lucēns.apache.org / solr /
- [2] Frenks Hofmans un Žakijs Kabeta: Ievads Apache Solr. 1. daļa, http: // linuxhint.com
- [3] Joniks Seelajs: Solr vaicājumu sintakse, http: // yonik.com / solr / vaicājuma-sintakse /
- [4] Joniks Seelajs: Solr apmācība, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: datu pieprasīšana, Tutorialspoint, https: // www.apmācības vieta.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucēna, https: // lucēns.apache.org /
- [7] SolrJ, https: // lucēns.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] čokurošanās, https: // čokurošanās.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.tīkls/
- [11] csvkit, https: // csvkit.lasāmie dokumenti.io / lv / jaunākais /


