Apache Spark ir datu analīzes rīks, ko var izmantot, lai apstrādātu datus no HDFS, S3 vai citiem atmiņas datu avotiem. Šajā ziņojumā mēs instalēsim Apache Spark uz Ubuntu 17.10 mašīna.
Ubuntu versija
Šajā rokasgrāmatā mēs izmantosim Ubuntu 17. versiju.10 (GNU / Linux 4.13.0-38-vispārīgs x86_64).
Apache Spark ir Hadoop lielo datu ekosistēmas sastāvdaļa. Mēģiniet instalēt Apache Hadoop un izveidojiet ar to lietojumprogrammas paraugu.
Esošo pakotņu atjaunināšana
Lai sāktu Spark instalēšanu, ir jāatjaunina mūsu mašīna ar jaunākajām pieejamajām programmatūras pakotnēm. Mēs to varam izdarīt ar:
sudo apt-get update && sudo apt-get -y dist-upgradeTā kā Spark pamatā ir Java, mums tas ir jāinstalē mūsu mašīnā. Mēs varam izmantot jebkuru Java versiju virs Java 6. Šeit mēs izmantosim Java 8:
sudo apt-get -y instalējiet openjdk-8-jdk-headlessLejupielādē Spark failus
Visas nepieciešamās paketes tagad ir mūsu mašīnā. Mēs esam gatavi lejupielādēt nepieciešamos Spark TAR failus, lai mēs varētu sākt tos iestatīt un palaist arī programmas Spark paraugu.
Šajā rokasgrāmatā mēs instalēsim Spark v2.3.0 pieejams šeit:
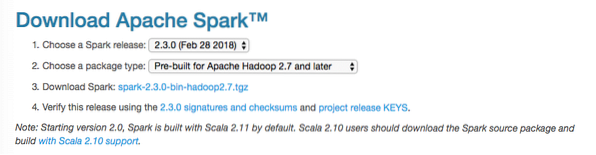
Dzirksteles lejupielādes lapa
Lejupielādējiet atbilstošos failus ar šo komandu:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / dzirksts-2.3.0-bin-hadoop2.7.tgzAtkarībā no tīkla ātruma tas var aizņemt dažas minūtes, jo fails ir liels:
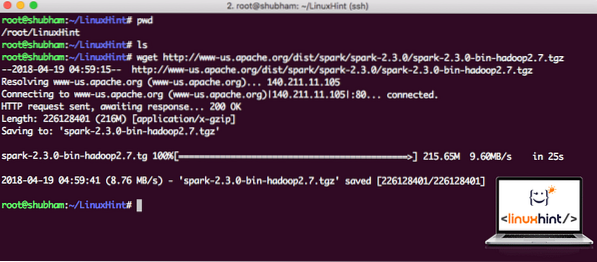
Lejupielādē Apache Spark
Tagad, kad mums ir lejupielādēts TAR fails, mēs varam iegūt pašreizējā direktorijā:
darva xvzf spark-2.3.0-bin-hadoop2.7.tgzTas aizņems dažas sekundes, jo arhīvā ir liels faila lielums:
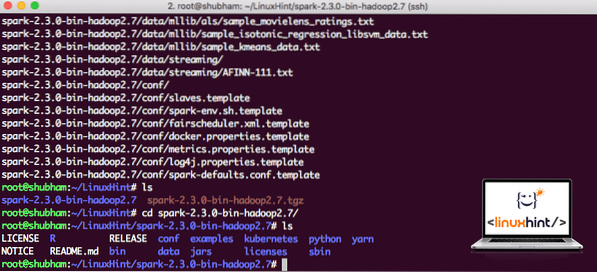
Arhivētie faili programmā Spark
Runājot par Apache Spark jaunināšanu nākotnē, tas var radīt problēmas ceļa atjauninājumu dēļ. No šiem jautājumiem var izvairīties, izveidojot saiti uz Spark. Palaidiet šo komandu, lai izveidotu programmatūras saiti:
ln -s spark-2.3.0-bin-hadoop2.7 dzirkstsDzirksteles pievienošana ceļam
Lai izpildītu Spark skriptus, mēs tos tagad pievienosim ceļam. Lai to izdarītu, atveriet failu bashrc:
vi ~ /.bashrcPievienojiet šīs rindas saraksta beigām .bashrc failu, lai ceļš varētu saturēt izpildāmā Spark faila ceļu:
SPARK_HOME = / LinuxHint / sparkeksportēt PATH = $ SPARK_HOME / bin: $ PATH
Tagad fails izskatās šādi:
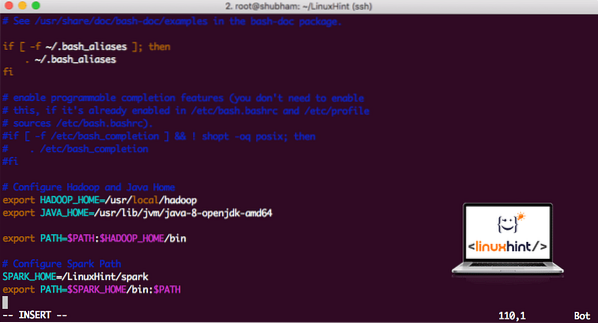
Dzirksteles pievienošana PATH
Lai aktivizētu šīs izmaiņas, palaidiet šādu komandu bashrc failam:
avots ~ /.bashrcPalaist Spark Shell
Tagad, kad mēs atrodamies tieši ārpus dzirksteļu direktorija, palaidiet šādu komandu, lai atvērtu apark apvalku:
./ dzirkstele / tvertne / dzirksteles apvalksMēs redzēsim, ka Spark apvalks tagad ir atvērts:
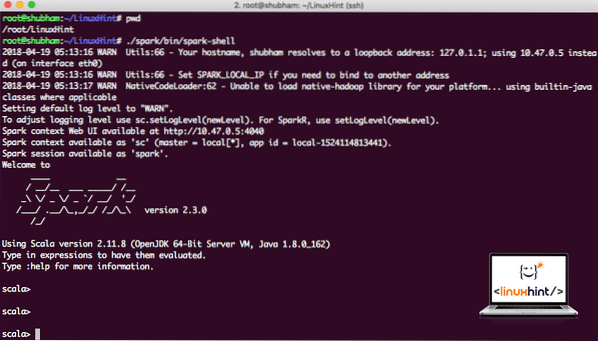
Palaist dzirksteles apvalku
Konsolē varam redzēt, ka Spark ir atvēris arī tīmekļa konsoli 404. portā. Apmeklēsim:
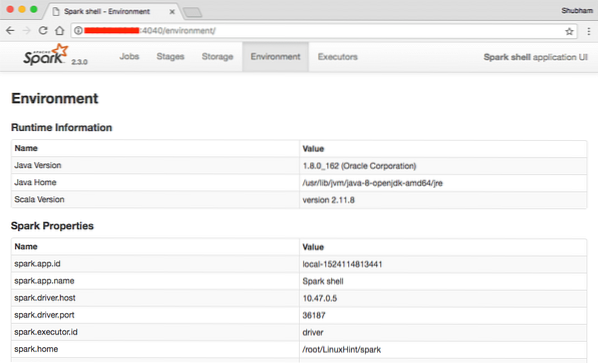
Apache Spark tīmekļa konsole
Lai gan mēs darbosimies pašā konsolē, tīmekļa vide ir svarīga vieta, uz kuru ir jāskatās, veicot smagus Spark Jobs darbus, lai jūs zinātu, kas notiek katrā jūsu izpildītajā Spark Job.
Pārbaudiet Spark apvalka versiju ar vienkāršu komandu:
sc.versijaMēs atgriezīsimies šādi:
res0: virkne = 2.3.0Spark lietojumprogrammas parauga izveidošana ar Scala
Tagad mēs izveidosim Word Counter lietojumprogrammas paraugu ar Apache Spark. Lai to izdarītu, vispirms ielādējiet teksta failu Spark Context uz Spark apvalka:
scala> var Dati = sc.textFile ("/ root / LinuxHint / spark / README.md ")Dati: org.apache.dzirkstele.rdd.RDD [virkne] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] at textFile vietnē: 24
scala>
Tagad failā esošais teksts ir jāsadala žetonos, kurus Spark var pārvaldīt:
scala> var tokens = Dati.flatMap (s => s.sadalīt (""))žetoni: org.apache.dzirkstele.rdd.RDD [virkne] = MapPartitionsRDD [2] pie flatMap pie: 25
scala>
Tagad inicializējiet katra vārda skaitu līdz 1:
scala> var tokens_1 = žetoni.karte (s => (s, 1))žetoni_1: org.apache.dzirkstele.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] kartē: 25
scala>
Visbeidzot, aprēķiniet katra faila vārda biežumu:
var sum_each = žetoni_1.reducByKey ((a, b) => a + b)Laiks aplūkot programmas izvadi. Savāc marķierus un to atbilstošo skaitu:
scala> sum_each.savākt ()res1: masīvs [(virkne, int)] = masīvs ((pakete, 1), (priekš, 3), (programmas, 1), (apstrāde.,1), (Tāpēc, 1), (The, 1), (lapa] (http: // dzirksts.apache.org / dokumentācija.html).,1), (kopa.,1), (tā, 1), ([palaist, 1), (nekā, 1), (API, 1), (ir, 1), (mēģināt, 1), (aprēķins, 1), (caur, 1 ), (vairāki, 1), (Šis, 2), (grafiks, 1), (Strops, 2), (uzglabāšana, 1), (["Norāda, 1), (Kam, 2), (" dzija " , 1), (Vienreiz, 1), (["Noderīgi, 1), (dod priekšroku, 1), (SparkPi, 2), (Dzinējs, 1), (versija, 1), (fails, 1), [dokumentācija ,, 1), (apstrāde ,, 1), (the, 24), (ir, 1), (sistēmas.,1), (params, 1), (nav, 1), (atšķirīgs, 1), (atsauce, 2), (interaktīvs, 2), (R ,, 1), (dots.,1), (ja, 4), (būvēt, 4), (kad, 1), (būt, 2), (Testi, 1), (Apache, 1), (pavediens, 1), (programmas ,, 1 ), (ieskaitot, 4), (./ bin / run-example, 2), (Spark.,1), (iepakojums.,1), (1000).skaits (), 1), (Versijas, 1), (HDFS, 1), (D…
scala>
Izcili! Mēs varējām palaist vienkāršu Word Counter piemēru, izmantojot Scala programmēšanas valodu ar teksta failu, kas jau atrodas sistēmā.
Secinājums
Šajā nodarbībā mēs apskatījām, kā mēs varam instalēt un sākt lietot Apache Spark Ubuntu 17.10 mašīnu un palaidiet tajā arī lietojumprogrammas paraugu.
Lasiet vairāk ziņas, kuru pamatā ir Ubuntu, šeit.


