Šajā rakstā mēs iepazīsimies ar grupas pēc funkcijas pamata lietojumiem pandas pitonā. Visas komandas tiek izpildītas Pycharm redaktorā.
Ar darbinieka datu palīdzību apspriedīsim grupas galveno koncepciju. Mēs esam izveidojuši datu ietvaru ar noderīgu darbinieku informāciju (Employee_Names, Designation, Employee_city, Age).
Stīgu savienošana, izmantojot grupu pēc funkcijas
Izmantojot funkciju groupby, varat sasaistīt virknes. Vienus šūnā tos pašus ierakstus var savienot ar “,”.
Piemērs
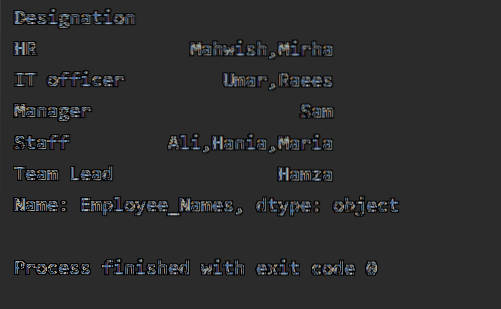
Šajā piemērā mēs esam sakārtojuši datus, pamatojoties uz darbinieku sleju “Apzīmējums” un pievienojušies darbiniekiem, kuriem ir vienāds apzīmējums. Funkcija lambda tiek lietota laukam 'Employees_Name'.
importa pandas kā pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karachi', 'Karači', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Apzīmējums") ['Employee_Names'].pieteikties (lambda Employee_Names: ','.pievienoties (Employee_Names))
drukāt (df1)
Kad tiek izpildīts iepriekš minētais kods, tiek parādīta šāda izeja:
Vērtību kārtošana augošā secībā
Izmantojiet groupby objektu parastā datu ietvarā, izsaucot '.to_frame () 'un pēc tam atkārtotai indeksēšanai izmantojiet reset_index (). Kārtot kolonnu vērtības, izsaucot sort_values ().
Piemērs
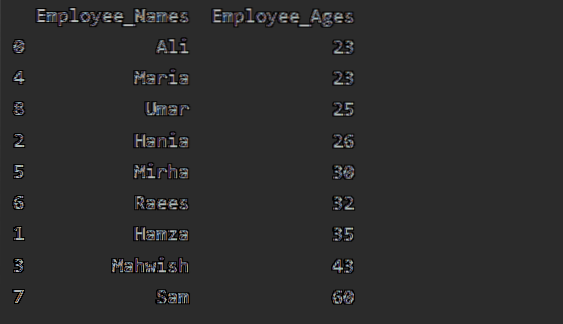
Šajā piemērā mēs kārtosim Darbinieka vecumu augošā secībā. Izmantojot šo koda daļu, mēs esam ieguvuši 'Employee_Age' augošā secībā ar 'Employee_Names'.
importa pandas kā pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karachi', 'Karači', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].summa ().ierāmēt().reset_index ().sort_values (pēc = 'Employee_Age')
drukāt (df1)
Agregātu izmantošana ar grupu
Ir pieejamas vairākas funkcijas vai apkopojumi, kurus varat izmantot datu grupās, piemēram, skaits (), summa (), vidējais (), mediāns (), režīms (), std (), min (), maks ().
Piemērs
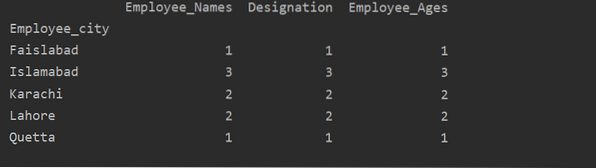
Šajā piemērā mēs esam izmantojuši funkciju “count ()” ar groupby, lai uzskaitītu darbiniekus, kas pieder tai pašai “Employee_city”.
importa pandas kā pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karachi', 'Karači', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').skaitīt ()
drukāt (df1)
Kā redzat šādu izvadi, kolonnās Apzīmējums, Darbinieka nosaukumi un Darbinieka vecums uzskaitiet numurus, kas pieder tai pašai pilsētai:
Vizualizējiet datus, izmantojot groupby
Izmantojot 'importēt matplotlib.pyplot ', varat vizualizēt savus datus diagrammās.
Piemērs
Šis piemērs vizualizē “Employee_Age” ar “Employee_Nmaes” no norādītā DataFrame, izmantojot groupby paziņojumu.
importa pandas kā pdimporta matplotlib.pyplot kā plt
datu ietvars = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karači', 'Karači', 'Islamabada', 'Islamabada', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
datu ietvars.groupby ('Darbinieku vārdi').summa ().sižets (kind = 'bar')
plt.rādīt ()
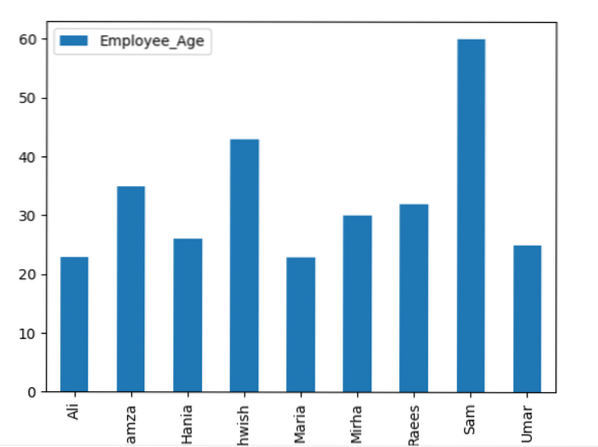
Piemērs
Lai attēlotu sakrauto diagrammu, izmantojot groupby, pagrieziet “stacked = true” un izmantojiet šādu kodu:
importa pandas kā pdimporta matplotlib.pyplot kā plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karachi', 'Karači', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).Izmērs().atkrāmēt ().plot (kind = 'bar', stacked = True, fontsize = '6')
plt.rādīt ()
Zemāk dotajā diagrammā sakrauto darbinieku skaits, kas pieder tai pašai pilsētai.
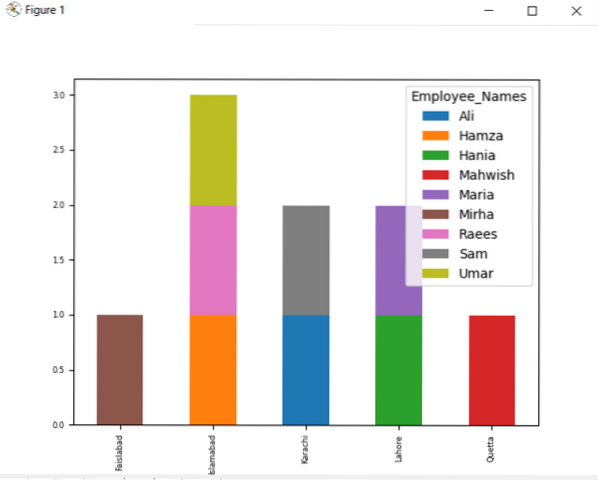
Mainiet kolonnas nosaukumu ar grupu pēc
Apkopoto kolonnas nosaukumu var mainīt arī ar kādu jaunu modificētu nosaukumu šādi:
importa pandas kā pdimporta matplotlib.pyplot kā plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karači', 'Karači', 'Islamabada', 'Islamabada', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Apzīmējums'].summa ().reset_index (name = 'Employee_Designation')
drukāt (df1)
Iepriekš minētajā piemērā nosaukums “Apzīmējums” tiek mainīts uz “Darbinieka_nosaukums”.
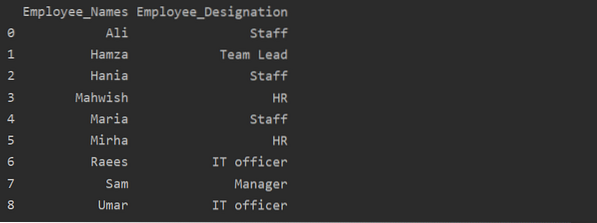
Iegūt grupu pēc atslēgas vai vērtības
Izmantojot paziņojumu groupby, no datu ietvara var izgūt līdzīgus ierakstus vai vērtības.
Piemērs
Tālāk sniegtajā piemērā mums ir grupas dati, kuru pamatā ir “Apzīmējums”. Pēc tam grupa "Personāls" tiek izgūta, izmantojot .getgroup ('Personāls').
importa pandas kā pdimporta matplotlib.pyplot kā plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karači', 'Karači', 'Islamabada', 'Islamabada', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
izvilkuma_vērtība = df.groupby (“Apzīmējums”)
izdrukāt (izvilkuma_vērtība.get_group ('Personāls'))
Izvades logā tiek parādīts šāds rezultāts:

Pievienojiet vērtību grupas sarakstam
Līdzīgus datus var parādīt saraksta veidā, izmantojot paziņojumu groupby. Vispirms grupējiet datus, pamatojoties uz nosacījumu. Pēc tam, izmantojot funkciju, jūs varat viegli ievietot šo grupu sarakstos.
Piemērs
Šajā piemērā mēs esam iekļāvuši līdzīgus ierakstus grupu sarakstā. Visi darbinieki tiek sadalīti grupā, pamatojoties uz 'Employee_city', un pēc tam, izmantojot funkciju 'Lambda', šī grupa tiek izgūta saraksta veidā.
importa pandas kā pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karači', 'Karači', 'Islamabada', 'Islamabada', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].piemērot (lambda grupas_sērijas: grupas_sērijas.uzskaitīt()).reset_index ()
drukāt (df1)
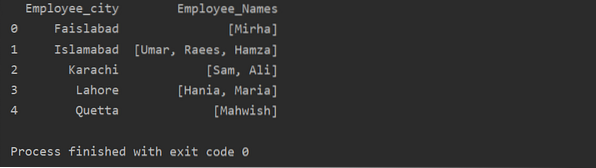
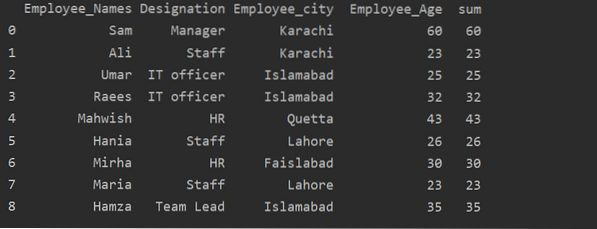
Transform funkcijas izmantošana ar groupby
Darbinieki tiek grupēti atbilstoši viņu vecumam, šīs vērtības saskaita kopā, un, izmantojot funkciju “pārveidot”, tabulā tiek pievienota jauna sleja:
importa pandas kā pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
“Apzīmējums”: [“vadītājs”, “personāls”, “IT virsnieks”, “IT virsnieks”, “personāls”, “personāls”, “personāls”, “personāls”, “komandas vadītājs”],
'Employee_city': ['Karači', 'Karači', 'Islamabada', 'Islamabada', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
“Darbinieka vecums”: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['summa'] = df.groupby (['Employee_Names']) ['Employee_Age'].pārveidot ('summa')
drukāt (df)
Secinājums
Šajā rakstā mēs esam izpētījuši dažādus grupas paziņojuma izmantošanas veidus. Mēs parādījām, kā jūs varat sadalīt datus grupās, un, izmantojot dažādus apkopojumus vai funkcijas, jūs varat viegli izgūt šīs grupas.

