Šajā rakstā ir parādīts, kā atrast dublikātus datos un noņemt dublikātus, izmantojot funkcijas Pandas Python.
Šajā rakstā mēs esam ņēmuši dažādu ASV štatu iedzīvotāju datu kopu, kas ir pieejama a .csv faila formāts. Mēs lasīsim .csv fails, lai parādītu šī faila sākotnējo saturu, šādi:
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
drukāt (df_state)
Šajā ekrānuzņēmumā varat redzēt šī faila satura dublikātu:
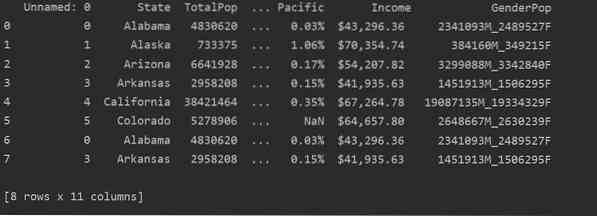
Dublikātu identificēšana Pandas Python
Ir jānosaka, vai jūsu izmantotajiem datiem ir dublētas rindas. Lai pārbaudītu datu dublēšanos, varat izmantot jebkuru no metodēm, kas aplūkotas nākamajās sadaļās.
1. metode:
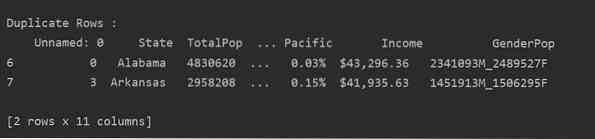
Izlasiet csv failu un pārsūtiet to datu rāmī. Pēc tam identificējiet rindu dublikātus, izmantojot dublikāts () funkciju. Visbeidzot, izmantojiet drukas paziņojumu, lai parādītu rindu dublikātus.
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
Dup_Rows = df_state [df_state.dublikāts ()]
print ("\ n \ nDublēt rindas: \ n ".formāts (Dup_Rows))
2. metode:
Izmantojot šo metodi, is_duplicate kolonna tiks pievienota tabulas beigās un dublētu rindu gadījumā tiks atzīmēta kā “True”.
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
df_state ["is_duplicate"] = df_state.dublikāts ()
drukāt ("\ n ".formāts (df_state))
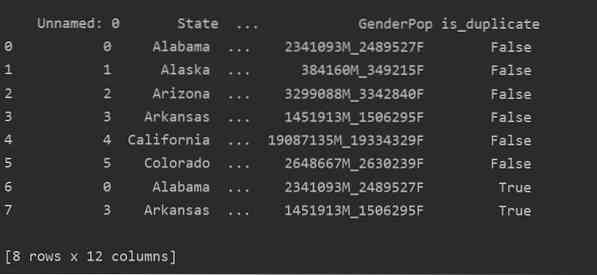
Dublikātu nomešana Pandas Python
Dublētas rindas no datu rāmja var noņemt, izmantojot šādu sintaksi:
drop_duplicates (apakškopa = ", keep =", inplace = False)
Iepriekš minētie trīs parametri nav obligāti un sīkāk paskaidroti zemāk:
saglabāt: šim parametram ir trīs dažādas vērtības: First, Last un False. Pirmā vērtība saglabā pirmo gadījumu un noņem nākamos dublikātus, Pēdējā vērtība saglabā tikai pēdējo gadījumu un noņem visus iepriekšējos dublikātus, un Vērtība False noņem visas dublētās rindas.
apakškopa: iezīme, ko izmanto, lai identificētu dublētās rindas
vietā: satur divus nosacījumus: Patiesi un Nepatiesi. Šis parametrs noņems dublētās rindas, ja tā būs iestatīta uz True.
Noņemiet dublikātus, saglabājot tikai pirmo gadījumu
Lietojot “keep = first”, tiks saglabāts tikai pirmais rindas gadījums, un visi pārējie dublikāti tiks noņemti.
Piemērs
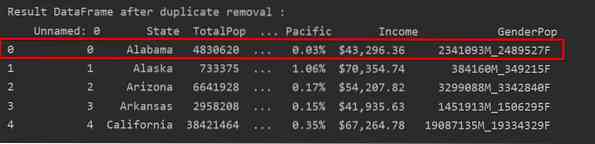
Šajā piemērā tiks saglabāta tikai pirmā rinda, un pārējie dublikāti tiks izdzēsti:
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
Dup_Rows = df_state [df_state.dublikāts ()]
print ("\ n \ nDublēt rindas: \ n ".formāts (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (saglabāt = 'pirmais')
print ('\ n \ nRezultāts DataFrame pēc dublikāta noņemšanas: \ n', DF_RM_DUP.galva (n = 5))
Šajā ekrānuzņēmumā saglabāts pirmās rindas gadījums ir izcelts sarkanā krāsā un tiek noņemtas atlikušās dublikācijas:
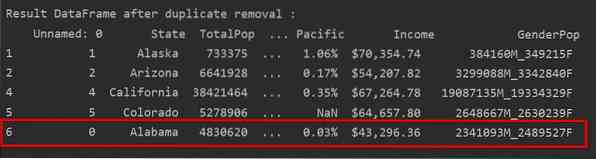
Noņemiet dublikātus, saglabājot tikai pēdējo gadījumu
Lietojot “keep = last”, tiks noņemtas visas rindu dublikāti, izņemot pēdējo gadījumu.
Piemērs
Šajā piemērā tiek noņemtas visas dublētās rindas, izņemot tikai pēdējo gadījumu.
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
Dup_Rows = df_state [df_state.dublikāts ()]
print ("\ n \ nDublēt rindas: \ n ".formāts (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = 'pēdējais')
print ('\ n \ nRezultāts DataFrame pēc dublikāta noņemšanas: \ n', DF_RM_DUP.galva (n = 5))
Šajā attēlā dublikāti tiek noņemti un tiek glabāts tikai pēdējais rindas gadījums:
Noņemt visas dublikātu rindas
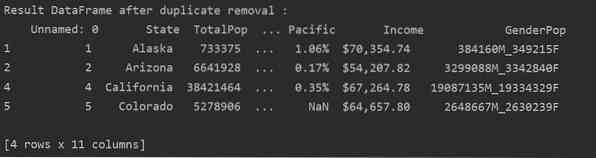
Lai noņemtu visas tabulas dublikātu rindas, iestatiet “keep = False” šādi:
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
Dup_Rows = df_state [df_state.dublikāts ()]
print ("\ n \ nDublēt rindas: \ n ".formāts (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (saglabāt = Nepatiesa)
print ('\ n \ nRezultāts DataFrame pēc dublikāta noņemšanas: \ n', DF_RM_DUP.galva (n = 5))
Kā redzat šajā attēlā, visi dublikāti tiek noņemti no datu rāmja:
Noņemiet saistītos dublikātus no norādītās kolonnas
Pēc noklusējuma funkcija pārbauda visas dublētās rindas no visām kolonnām dotajā datu rāmī. Bet arī kolonnas nosaukumu varat norādīt, izmantojot apakškopas parametru.
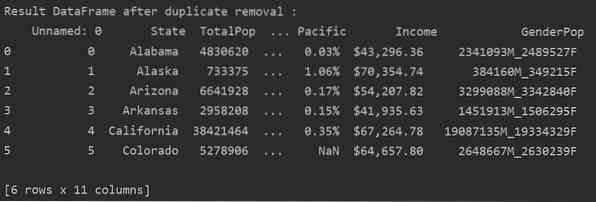
Piemērs
Šajā piemērā visi saistītie dublikāti tiek noņemti no kolonnas “Valstis”.
importa pandas kā pddf_state = pd.lasīt_csv ("C: / Lietotāji / DELL / Darbvirsma / populācijas_ds.csv ")
Dup_Rows = df_state [df_state.dublikāts ()]
print ("\ n \ nDublēt rindas: \ n ".formāts (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (apakškopa = 'Valsts')
print ('\ n \ nRezultāts DataFrame pēc dublikāta noņemšanas: \ n', DF_RM_DUP.galva (n = 6))
Secinājums
Šis raksts parādīja, kā noņemt dublētas rindas no datu rāmja, izmantojot drop_duplicates () funkcija Pandas Python. Izmantojot šo funkciju, varat arī notīrīt datus no dublēšanās vai atlaišanas. Raksts arī parādīja, kā identificēt visus datu kopijas dublikātus.


