Šis pārskats ir nedaudz abstrakts, tāpēc pamatosim to reālās situācijas scenārijā, iedomājieties, ka jums jāuzrauga vairāki tīmekļa serveri. Katram ir sava vietne, un katrā no tām katru dienu katru sekundi tiek nepārtraukti ģenerēti jauni žurnāli. Papildus tam ir vairāki e-pasta serveri, kas jums arī jāuzrauga.
Šie dati, iespējams, būs jāuzglabā lietvedības un rēķinu sagatavošanas nolūkos, kas ir pakešdarbs, kuram nav nepieciešama tūlītēja uzmanība. Iespējams, vēlēsities veikt datu analīzi, lai reāllaikā pieņemtu lēmumus, kas prasa precīzu un tūlītēju datu ievadi. Pēkšņi jums rodas nepieciešamība saprātīgi racionalizēt datus dažādām vajadzībām. Kafka darbojas kā tas abstrakcijas slānis, kuram vairāki avoti var publicēt dažādas datu plūsmas un doto patērētājs var abonēt straumes, kuras tā uzskata par būtiskām. Kafka pārliecināsies, ka dati ir pareizi sakārtoti. Tas ir Kafka iekšējais elements, kas mums jāsaprot, pirms nonākam pie sadaļas Partitioning and Keys tēmas.
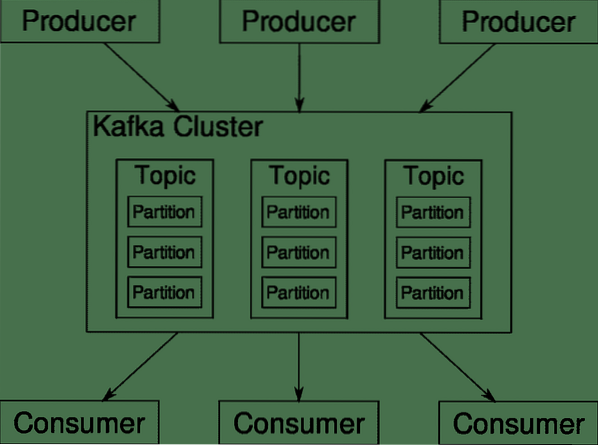
Kafka tēmas, brokeris un starpsienas
Kafka Tēmas ir kā datu bāzes tabulas. Katra tēma sastāv no datiem no noteikta veida avota. Piemēram, klastera veselība var būt tēma, kas sastāv no centrālā procesora un atmiņas izmantošanas informācijas. Līdzīgi ienākošā trafika pāri klasterim var būt vēl viena tēma.
Kafka ir veidota tā, lai tā būtu horizontāli mērogojama. Tas ir, viens Kafka gadījums sastāv no vairākiem Kafka brokeri darbojas vairākos mezglos, katrs var apstrādāt datu plūsmas paralēli otrai. Pat ja daži no mezgliem neizdodas, jūsu datu cauruļvads var turpināt darboties. Pēc tam konkrētu tēmu var sadalīt vairākās starpsienas. Šī sadalīšana ir viens no izšķirošajiem faktoriem, kas nosaka Kafka horizontālo mērogojamību.
Vairāki ražotājiem, datu avoti par konkrētu tēmu, var rakstīt uz šo tēmu vienlaikus, jo katrs raksta citā nodalījumā, jebkurā brīdī. Tagad parasti nodalījumam dati tiek piešķirti nejauši, ja vien mēs to nenodrošinām ar atslēgu.
Sadalīšana un pasūtīšana
Atgādinot, ražotāji raksta datus par noteiktu tēmu. Šī tēma faktiski ir sadalīta vairākos nodalījumos. Katrs nodalījums dzīvo neatkarīgi no citiem, pat attiecībā uz noteiktu tēmu. Tas var radīt daudz neskaidrību, ja pasūtīšana uz datiem ir svarīga. Varbūt jums dati ir nepieciešami hronoloģiskā secībā, taču, ja datu straumei ir vairāki nodalījumi, tas negarantē nevainojamu pasūtīšanu.
Katrai tēmai varat izmantot tikai vienu nodalījumu, bet tas pārkāpj visu Kafka izplatītās arhitektūras mērķi. Tāpēc mums ir nepieciešams kāds cits risinājums.
Starpsienu atslēgas
Dati no ražotāja uz nodalījumiem tiek nosūtīti nejauši, kā mēs jau minējām iepriekš. Ziņojumi ir faktiskie datu gabali. Ražotāji var darīt ne tikai ziņojumu sūtīšanu, bet arī pievienot tam pievienoto atslēgu.
Visi ziņojumi, kas nāk ar konkrēto atslēgu, nonāks tajā pašā nodalījumā. Tā, piemēram, lietotāja darbību var izsekot hronoloģiski, ja šī lietotāja dati tiek atzīmēti ar atslēgu, un tāpēc tie vienmēr nonāk vienā nodalījumā. Sauksim šo nodalījumu p0 un lietotāju u0.
Partition p0 vienmēr uzņems ar u0 saistītos ziņojumus, jo šī atslēga tos saista. Bet tas nenozīmē, ka p0 ir saistīts tikai ar to. Tas var arī uzņemt ziņojumus no u1 un u2, ja tam ir iespējas to darīt. Līdzīgi citi nodalījumi var patērēt datus no citiem lietotājiem.
Punkts, ka konkrēta lietotāja dati nav izplatīti pa dažādiem nodalījumiem, nodrošinot šī lietotāja hronoloģisko secību. Tomēr vispārējā tēma lietotāja dati, joprojām var izmantot Apache Kafka izplatīto arhitektūru.
Secinājums
Lai gan tādas izplatītas sistēmas kā Kafka atrisina dažas vecākas problēmas, piemēram, mērogojamības trūkums vai viena kļūme. Viņi nāk ar problēmu kopumu, kas raksturīgs tikai viņu pašu dizainam. Šo problēmu paredzēšana ir būtisks jebkura sistēmas arhitekta darbs. Ne tikai tas, ka dažreiz jums patiešām ir jāveic izmaksu un ieguvumu analīze, lai noteiktu, vai jaunās problēmas ir cienīgs kompromiss, lai atbrīvotos no vecākajām. Pasūtīšana un sinhronizācija ir tikai aisberga virsotne.
Cerams, ka šādi raksti un oficiālā dokumentācija var jums palīdzēt.


