Šī emuāra kods kopā ar datu kopu ir pieejams šajā saitē https: // github.com / shekharpandey89 / k-nozīmē
K-Means klasterošana ir bez uzraudzības mašīnmācīšanās algoritms. Ja salīdzinām K-Means bez uzraudzības klasterizācijas algoritmu ar uzraudzīto algoritmu, nav nepieciešams apmācīt modeli ar iezīmētajiem datiem. K-Means algoritmu izmanto, lai dažādus objektus klasificētu vai grupētu pēc to atribūtiem vai pazīmēm K grupu skaitā. Šeit K ir vesels skaitlis. K-Means aprēķina attālumu (izmantojot attāluma formulu) un pēc tam atrod minimālo attālumu starp datu punktiem un centrālās kopas, lai klasificētu datus.
Sapratīsim K-līdzekļus, izmantojot mazo piemēru, izmantojot 4 objektus, un katram objektam ir 2 atribūti.
| ObjektiNosaukums | Atribūts_X | Atribūts_Y |
|---|---|---|
| M1 | 1 | 1 |
| M2 | 2 | 1 |
| M3 | 4 | 3 |
| M4 | 5 | 4 |
K-nozīmē atrisināt skaitlisku piemēru:
Lai atrisinātu iepriekš minēto skaitlisko problēmu, izmantojot K-Means, mums ir jāveic šādas darbības:
K-Means algoritms ir ļoti vienkāršs. Pirmkārt, mums ir jāizvēlas jebkurš nejaušs K skaitlis un pēc tam jāizvēlas kopas centri vai centrs. Lai izvēlētos centroidus, mēs varam izvēlēties jebkuru nejaušu objektu skaitu inicializēšanai (atkarīgs no K vērtības).
K-Means algoritma pamatdarbības ir šādas:
- Turpina skriet, kamēr neviens objekts nepārvietojas no centra centra (stabils).
- Vispirms dažus centrīdus izvēlamies nejauši.
- Pēc tam mēs nosakām attālumu starp katru objektu un centraīdiem.
- Objektu grupēšana, pamatojoties uz minimālo attālumu.
Tātad katram objektam ir divi punkti kā X un Y, un tie grafika telpā ir šādi:
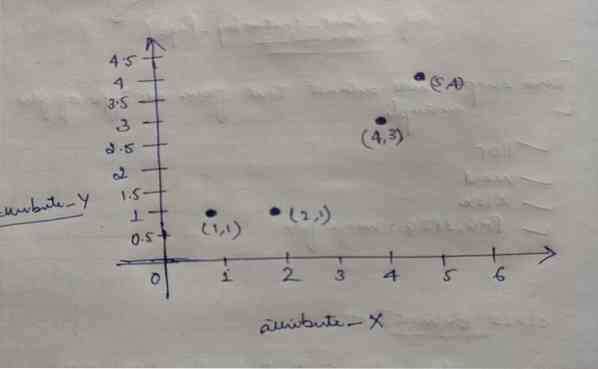
Tāpēc mēs sākotnēji izvēlamies K = 2 vērtību kā nejaušu, lai atrisinātu mūsu iepriekš minēto problēmu.
1. solis: Sākotnēji mēs izvēlamies pirmos divus objektus (1, 1) un (2, 1) kā mūsu centraīdus. Zemāk redzamais grafiks parāda to pašu. Mēs šos centrīdus saucam par C1 (1, 1) un C2 (2,1). Šeit mēs varam teikt, ka C1 ir grupa_1 un C2 ir grupa_2.
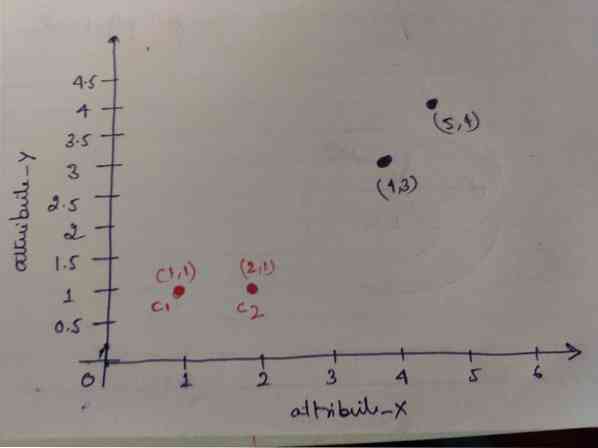
2. solis: Tagad mēs aprēķināsim katra objekta datu punktu uz centroidiem, izmantojot Eiklida attāluma formulu.
Lai aprēķinātu attālumu, mēs izmantojam šādu formulu.

Mēs aprēķinām attālumu no objektiem līdz centrālajiem mezgliem, kā parādīts zemāk esošajā attēlā.

Tātad, mēs aprēķinājām katra objekta datu punkta attālumu, izmantojot iepriekš minēto attāluma metodi, un beidzot ieguva attāluma matricu, kā norādīts zemāk:
DM_0 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) kopa1 | grupa_1 |
| 1 | 0 | 2.83 | 4.24 | C2 = (2,1) kopa2 | grupa_2 |
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | X |
| 1 | 1 | 3 | 4 | Jā |
Tagad mēs aprēķinājām katra objekta attāluma vērtību katram centroidam. Piemēram, objekta punktiem (1,1) attāluma vērtība līdz c1 ir 0 un c2 ir 1.
No iepriekš minētās attāluma matricas mēs uzzinām, ka objektam (1, 1) ir attālums līdz kopai1 (c1) ir 0 un līdz kopai2 (c2) ir 1. Tātad viens objekts ir tuvu pašam klasterim1.
Līdzīgi, ja pārbaudām objektu (4, 3), attālums līdz 1. kopai ir 3.61 un 2. klasterim ir 2.83. Tātad objekts (4, 3) pāriet uz 2. kopu.
Līdzīgi, ja pārbaudāt objektu (2, 1), attālums līdz 1. klasterim ir 1 un līdz 2. klasterim ir 0. Tātad, šis objekts tiks pārvietots uz 2. kopu.
Tagad, atbilstoši to attāluma vērtībai, mēs grupējam punktus (objektu kopas).
G_0 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | grupa_1 |
| 0 | 1 | 1 | 1 | grupa_2 |
Tagad, atbilstoši to attāluma vērtībai, mēs grupējam punktus (objektu kopas).
Visbeidzot, diagramma pēc klasterizācijas veikšanas izskatīsies šādi: (G_0).
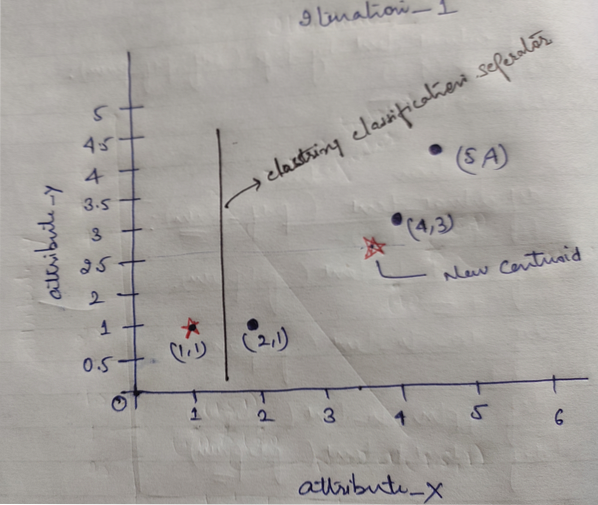
Atkārtojums_1: Tagad mēs aprēķināsim jaunus centraīdus, kad sākotnējās grupas mainīsies attāluma formulas dēļ, kā parādīts G_0. Tātad grupai_1 ir tikai viens objekts, tāpēc tās vērtība joprojām ir c1 (1,1), bet grupai_2 ir 3 objekti, tāpēc tās jaunā centrālā vērtība ir 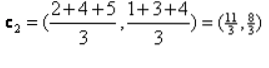
Tātad, jaunie c1 (1,1) un c2 (3.66, 2.66)
Tagad mums atkal jāaprēķina viss attālums līdz jaunajiem centraīdiem, kā mēs aprēķinājām iepriekš.
DM_1 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) kopa1 | grupa_1 |
| 3.14 | 2.36 | 0.47 | 1.89 | C2 = (3.66,2.66) kopa2 | grupa_2 |
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | X |
| 1 | 1 | 3 | 4 | Jā |
Iterācija_1 (objektu kopēšana): Tagad jaunā attāluma matricas (DM_1) aprēķina vārdā mēs to grupējam atbilstoši tam. Tātad, mēs pārvietojam M2 objektu no grupas_2 uz grupu_1 kā minimālā attāluma līdz centrālajiem punktiem likumu, un pārējais objekts būs tāds pats. Tātad jauna kopu veidošana būs tāda, kā zemāk.
G_1 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | grupa_1 |
| 0 | 0 | 1 | 1 | grupa_2 |
Tagad mums vēlreiz jāaprēķina jaunie centraīdi, jo abiem objektiem ir divas vērtības.
Tātad, jauni centraīdi būs 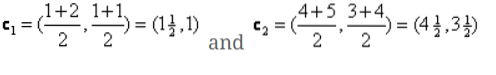
Tātad, pēc tam, kad būsim ieguvuši jaunos centraīdus, kopas izskatīsies šādi:
c1 = (1.5, 1)
c2 = (4.5, 3.5)
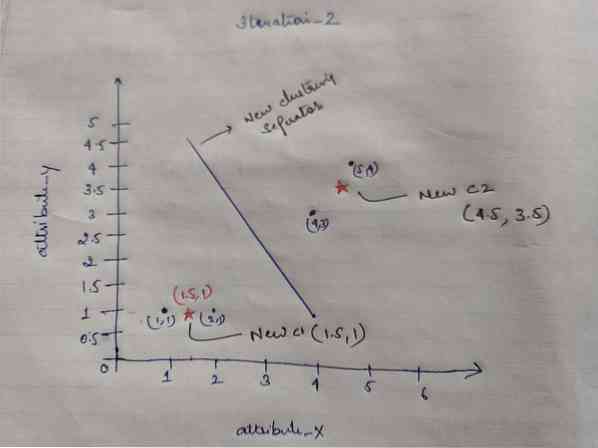
Atkārtojums_2: Mēs atkārtojam soli, kurā mēs aprēķinām katra objekta jauno attālumu līdz jaunajiem aprēķinātajiem centroidiem. Tātad pēc aprēķina mēs iegūsim šādu iterācijas_2 matricu.
DM_2 =
| 0.5 | 0.5 | 3.20 | 4.61 | C1 = (1.5, 1) kopa1 | grupa_1 |
| 4.30 | 3.54. lpp | 0.71 | 0.71 | C2 = (4.5, 3.5) kopa2 | grupa_2 |
A B C D
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | X |
| 1 | 1 | 3 | 4 | Jā |
Atkal mēs veicam grupēšanas uzdevumus, pamatojoties uz minimālo attālumu, kā mēs to darījām iepriekš. Tātad pēc tam mēs saņēmām klasterizācijas matricu, kas ir tāda pati kā G_1.
G_2 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | grupa_1 |
| 0 | 0 | 1 | 1 | grupa_2 |
Kā šeit, G_2 == G_1, tāpēc turpmāka atkārtošana nav nepieciešama, un mēs varam apstāties šeit.
K-nozīmē ieviešana, izmantojot Python:
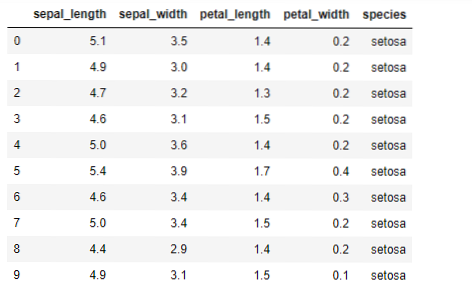
Tagad mēs ieviesīsim K-vidēja līmeņa algoritmu pitonā. Lai ieviestu K-līdzekļus, mēs izmantosim slaveno Iris datu kopu, kas ir atvērtā koda. Šajā datu kopā ir trīs dažādas klases. Šai datu kopai pamatā ir četras funkcijas: Klejlapas garums, sepalas platums, ziedlapas garums un ziedlapas platums. Pēdējā kolonnā būs norādīts šīs rindas klases nosaukums, piemēram, setosa.
Datu kopa izskatās šādi:
Python k-mean ieviešanai mums jāimportē nepieciešamās bibliotēkas. Tātad no sklearn importējam Pandas, Numpy, Matplotlib un arī KMeans.redaktors, kā norādīts zemāk:

Mēs lasām Irisu.csv datu kopa, izmantojot panda read_csv metodi, un parādīs 10 labākos rezultātus, izmantojot head metodi.
Tagad mēs lasām tikai tās datu kopas funkcijas, kuras mums vajadzēja modeļa apmācībai. Tātad mēs lasām visas četras datu kopu iezīmes (sepal garums, sepal platums, ziedlapas garums, ziedlapas platums). Šim nolūkam mēs četras indeksa vērtības [0, 1, 2, 3] nodevām pandas datu rāmja iloc funkcijai (df), kā parādīts zemāk:
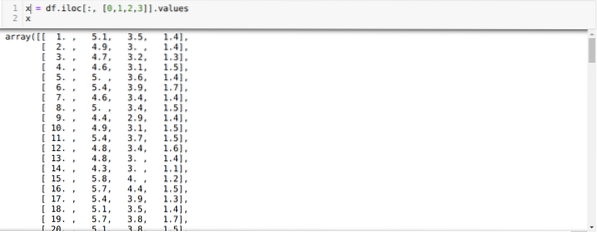
Tagad mēs nejauši izvēlamies kopu skaitu (K = 5). Mēs izveidojam K-klases klases objektu un pēc tam ievietojam mūsu x datu kopu apmācībai un prognozēšanai, kā parādīts zemāk:
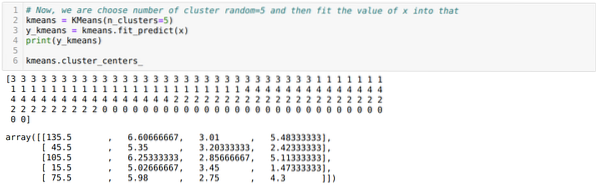
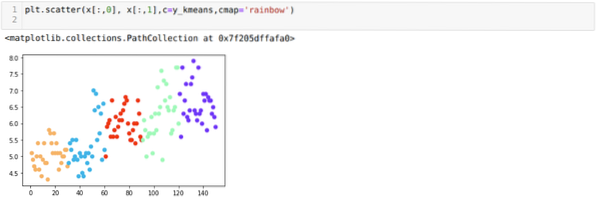
Tagad mēs vizualizēsim savu modeli ar nejaušu K = 5 vērtību. Mēs skaidri redzam piecas kopas, taču izskatās, ka tā nav precīza, kā parādīts zemāk.
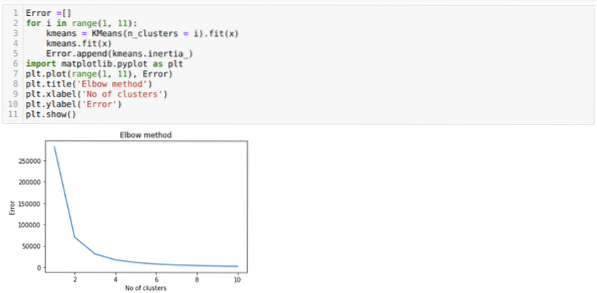
Tātad mūsu nākamais solis ir noskaidrot, vai klasteru skaits bija precīzs, vai nē. Un tam mēs izmantojam Elbow metodi. Elkona metodi izmanto, lai noskaidrotu optimālo kopas skaitu konkrētai datu kopai. Šo metodi izmantos, lai uzzinātu, vai k = 5 vērtība bija pareiza vai nē, jo mēs nesaņemam skaidru kopu kopu. Tātad pēc tam mēs ejam uz nākamo grafiku, kas parāda, ka K = 5 vērtība nav pareiza, jo optimālā vērtība ir no 3 līdz 4.
Tagad mēs atkal palaidīsim iepriekš minēto kodu ar kopu skaitu K = 4, kā parādīts zemāk:
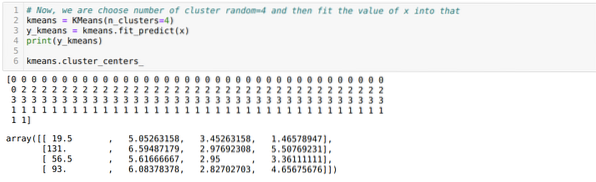
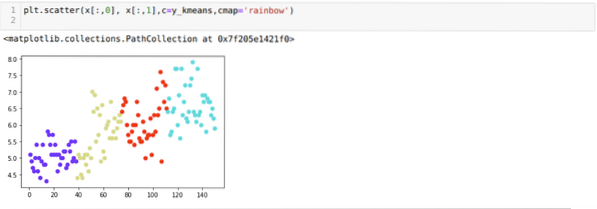
Tagad mēs vizualizēsim iepriekš minēto K = 4 jauno būvju kopu. Zemāk redzamajā ekrānā redzams, ka tagad kopu veidošana notiek ar k-līdzekļiem.
Secinājums
Tātad, mēs pētījām K-vidējo algoritmu gan skaitliskajā, gan pitona kodā. Mēs esam arī redzējuši, kā mēs varam uzzināt kopu skaitu konkrētai datu kopai. Dažreiz Elkona metode nevar dot pareizu kopu skaitu, tāpēc tādā gadījumā mēs varam izvēlēties vairākas metodes.

